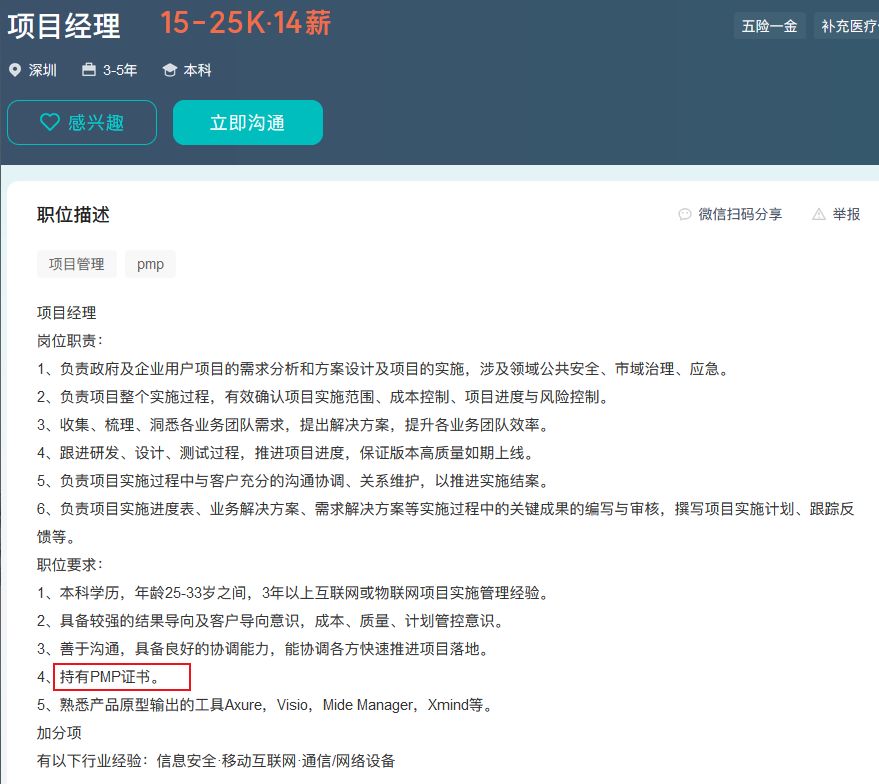
摘要
https://arxiv.org/pdf/2406.16860v1
我们介绍了Cambrian-1,这是一系列以视觉为中心的多模态大型语言模型(MLLMs)。尽管更强大的语言模型可以增强多模态能力,但视觉组件的设计选择往往没有得到充分的探索,并且与视觉表示学习研究脱节。这种差距阻碍了现实世界场景中准确的感官定位。我们的研究使用LLMs和视觉指令调优作为接口来评估各种视觉表示,基于超过20个视觉编码器的实验,为不同的模型和架构(基于自监督、强监督或两者的组合)提供了新的见解。我们批判性地检查了现有的MLLM基准测试,解决了在整合和解释来自各种任务的结果时遇到的困难,并引入了一个新的以视觉为中心的基准测试CV-Bench。为了进一步提高视觉定位,我们提出了空间视觉聚合器(SVA),这是一种动态且空间感知的连接器,它将高分辨率的视觉特征与LLMs集成在一起,同时减少了标记的数量。此外,我们还讨论了从公开可用来源中整理高质量视觉指令调优数据的重要性,强调了数据源平衡和分布比例的重要性。综合来看,Cambrian-1不仅达到了最先进的性能,还作为一套全面的、开放的食谱,用于指令调优的MLLMs。我们提供了模型权重、代码、支持工具、数据集以及详细的指令调优和评估方案。我们希望我们的发布能够激发并加速多模态系统和视觉表示学习领域的进步。
1. 引言
哲学界长期以来一直存在着关于语言中的理解和意义是否需要感官基础的争论。亚里士多德强调通过感官体验和经验观察来获取知识,这是其古代逍遥学派的核心思想,至今仍具有影响力[7];阿奎那在13世纪以逍遥学派公理的形式著名地阐述了这些观点:“Nihil est in intellectu quod non sit prius in sensu”(在理智中不存在的事物,必先在感官中存在)[6]。尽管许多哲学家持不同意见[18],但显而易见的是,拥有强大且高度可靠的感官基础至少是有益的。以寒武纪生命大爆发为例,人们普遍认为视觉的出现对于早期动物来说至关重要,不仅有助于它们寻找食物和避免捕食者,还有助于它们的进化和改进[98]。事实上,人类的大多数知识(以及几乎所有动物的知识)都是通过像视觉、听觉、触觉、味觉和嗅觉这样的感官体验,与物理世界的互动来获取的[100]。这些感官体验是理解我们周围世界的基础,对于现实世界的行动和决策至关重要。
除了哲学辩论之外,最近在多模态大型语言模型(MLLMs)方面的进展已经将视觉表示学习与语言理解的主题带入了实际应用的焦点。语言模型显示出强大的扩展性[48],而最近在多模态学习方面的进步在很大程度上是由更好、更大的LLMs的发展所推动的[74]。另一方面,视觉组件的设计选择往往没有得到充分的探索,并且与视觉表示学习研究脱节。例如,许多开创性的框架,如LLaVA[75],使用基于视觉Transformer的CLIP模型[102, 136]作为视觉特征提取器,这些模型通过语言进行强监督$ { }^{1}$。虽然也在探索其他视觉表示,如自监督的DINO[96][117],但这一领域缺乏全面和系统的研究。这种差距主要存在是因为这类研究具有挑战性:MLLMs涉及复杂的训练和评估流程,需要考虑众多设计决策。在这项工作中,我们旨在通过从视觉中心化的角度探索MLLMs来弥补这一差距。更具体地说,我们将MLLM指令调优作为评估各种视觉表示(如图1所示)的协议。
我们进行这项研究的动机还源于当前多模态学习研究的两个潜在问题:1) 过早地过度依赖语言可能成为一种捷径[40, 135],从而补偿了学习有效视觉表示的不足;2) 现有的基准可能无法为真实世界场景提供足够的指导,在这些场景中,视觉定位对于稳健的多模态理解至关重要。这些担忧并非没有根据,因为研究人员已经开始注意到,尽管在提高一般能力方面取得了显著进展[35,117,127],但在将MLLMs应用于一些具有挑战性的真实世界应用中时,视觉定位正在成为瓶颈。
从另一个角度来看,传统的视觉表示学习评估协议(例如,在ImageNet-1K[105]、COCO[72]和ADE20K[145]等数据集上进行线性探测和端到端微调)已经趋于饱和,无法反映真实世界分布中发现的多样化感知挑战。另一方面,以视觉问题回答(VQA)形式的语言提供了一种灵活且稳健的评估协议。我们的研究旨在探索这一新的协议设计,通过这一设计获得见解,以指导未来开发更好的视觉表示。此外,为了在这种综合环境中更好地评估视觉表示,我们将传统视觉基准转换为VQA格式,开发了一个以视觉为中心的MLLM基准“CV-Bench”(第3.2节)。
Cambrian-1围绕五个关键支柱构建,每个支柱都为MLLMs的设计空间提供了重要见解:
- 视觉表示:我们探索了各种视觉编码器及其组合。\S 3.4
- 连接器设计:我们设计了一种新的动态且空间感知的连接器,将视觉特征与LLMs相结合,同时减少了令牌的数量。\S 4
- 指令调优数据:我们从公共来源中精选高质量的视觉指令调优数据,强调分布平衡的重要性。\S 5
- 指令调优方法:我们讨论了指令调优的策略和实践。\S 3.3
- 基准测试:我们分析了现有的MLLM基准,将它们聚类为4个直观的组,并介绍了一个新的以视觉为中心的基准“CV-Bench”。\S 3.1, \S 3.2
作为我们探索的副产品,Cambrian-1引入了一系列在多样化基准测试中达到顶级性能并擅长视觉中心任务的最新MLLM(多模态大型语言模型)(第6节)。我们提供了模型权重、开源代码、数据集以及模型训练和评估的详细指南。我们希望我们的工作能够加强开放研究社区,并加速视觉表示学习和多模态系统领域的研究。
- 多模态LLMs:初步和相关工作
MLLM研究的关键组成部分包括大型语言模型、视觉编码器、多模态连接器、数据整理流程、指令调优策略和评估 E \mathcal{E} E基准。每个组件都有其复杂性,理解它们之间的相互作用提出了重大挑战。我们的研究从视觉中心的角度调查了这些方面。
大型语言模型 先进的LLMs[3, 94, 118, 119]是MLLM的基础。在对多模态数据进行指令调优后,这些模型可以被提示解决各种复杂的任务,并利用来自视觉编码器的输入生成自由形式的响应。最近的MLLM研究专注于增强LLM主干[9, 68, 74],从而在MMMU[134]和AI2D[47]等基准测试中取得了更好的性能。然而,这种改进引发了担忧,即我们当前的多模态评估被LLM的发展所偏袒,忽略了视觉感知的真正评估。例如,一些基准测试如MMMU[134]主要由LLM能力主导,这凸显了需要真正评估多模态性的评价(见第3.1节)。
视觉编码器 大多数MLLM使用像CLIP[102, 113, 136]这样的语言监督模型,这些模型受益于大规模带噪声的网页图像-文本数据。然而,还有更广泛的视觉模型仅使用视觉信号来学习表示,如自监督模型[8, 96]、分割[61]、深度监督[67]和扩散模型[104](见图2)。最近的工作[80,117]提倡将这些多样化的视觉模型整合到MLLM中。在这项研究中,我们系统地检查了各种视觉主干对MLLM性能的影响(第2节),并探索了模型组合的益处(第3.5节)。
多模态连接器 来自视觉编码器的表示不能直接由LLM处理——它们必须通过连接器映射到LLM的令牌空间。连接器设计主要有三种方法:重采样器[5]、Q-Former[10, 31]和MLP投影器[73, 75]。我们使用MLP投影器开始我们的探索,它非常有效但也存在挑战:视觉令牌的数量随着图像分辨率的增加而呈二次增长,限制了上下文长度输入分辨率的扩展。例如,LLaVA-Next[74]需要2880个视觉令牌来处理一个672px的图像。为了解决这个问题,我们探索了新的视觉连接器设计,这些设计在处理高分辨率图像的同时保持较少的视觉令牌数量(第4节)。
指令调优数据 视觉指令调优数据至关重要但难以收集,因为它很少自然存在于互联网上。以前的工作[31, 73, 91]将现有的VQA基准[43,62]转换为指令调优数据,显著提高了MLLM的性能。受此启发,我们收集了所有我们能找到的VQA基准和视觉交互数据(图9),研究了数据平衡和类别混合(第5.2节),并开发了一个互联网数据收集引擎来填补空白(第5.1节)。
指令调优 目前大多数MLLMs利用预训练的LLMs和视觉编码器,使用视觉指令调优数据对LLM和连接器进行微调。关于调优方案的一些方面存在争议,包括是否在与LLM联合微调之前先预训练连接器,以及在微调过程中是否冻结或解冻视觉编码器[56, 91]。此外,一些最近的专有模型探索了从头开始进行端到端的训练[42, 95]。在这项工作中,我们使用预训练模型并重新研究有争议的配方方面,通过广泛的研究为未来MLLM研究提供更多见解(第3.3节)。
评估与基准测试 有一系列基准测试集用于评估MLLMs的各个方面,如感知[39, 76]、知识[84, 85]、图表解释[77, 89]和视觉能力[117, 127]。我们主张不要过度优化特定基准测试集,而是倡导检查专注于特定能力的基准测试集的集合。为了实现这一点,我们分析了现有的基准测试集,对它们进行了分类,并评估了它们衡量多模态性的程度(第3.1节)。此外,我们发现目前很少有专注于以视觉为中心的评估的基准测试集,而现有的基准测试集中包含的图像相对较少,导致评估时的方差较高。为了解决这个问题,我们提出了一个新的以视觉为中心的基准测试集,通过重新制定经典视觉任务来实现(第3.2节)。
- 通过MLLMs评估视觉表示
当前的MLLMs主要依赖CLIP[102]作为视觉编码器,因为它预先与语言对齐且易于适应LLM的令牌空间。然而,强大的语言先验可能是一把双刃剑——它们补偿了学习有效视觉表示的不足[117],并削弱了从广泛的视觉表示学习研究中获得的见解。在本节中,我们系统地评估了不同的视觉编码器选择(见图2)如何影响MLLMs的多模态能力。我们还主张使用MLLM评估作为评估视觉表示方法的稳健框架,超越传统的线性探测和端到端微调等协议,以更真实地反映现实世界中多样化的感知挑战,并更好地指导改进视觉表示的开发。具体来说,在本节中我们:
§3.1. 分析基准测试集
§3.2. 引入CV-Bench
§3.3. 研究指令调优方案
§3.4. 使用MLLMs作为视觉表示评估器
3.5 3.5 3.5. 调查结合多个视觉编码器
3.1. 分析基准测试集
为了有效地评估视觉表示和MLLMs,我们首先需要选择能够准确评估这些模型多模态能力的基准测试集。我们使用了一组常用的基准测试集[19,39,47,50,76,77,84,85,89,112,117,128,134],这些测试集是最近MLLM研究中使用的测试集的交集[68, 70, 128]。为了帮助解释我们的结果,我们首先分析这些基准测试集本身。在这里,我们使用来自不同模型家族(见图2)的23种不同的视觉主干(见表9)来训练MLLMs,采用最初在[75]中提出的两阶段指令调优过程:首先使用ShareGPT-4V[22]中的120万适配器数据训练连接器,然后在737K指令调优数据上微调连接器和LLM(更多细节见附录E.5和F)。完整的基准测试结果见表10。
是LLM还是MLLM在回答问题?确定一个基准测试集是否真正需要视觉输入才能解决一直是视觉-语言研究中的一个持久挑战[2, 21, 43, 87]。在这项研究中,我们比较了MLLMs在有视觉输入和无视觉输入{2}下的性能,还计算了随机猜测的预期分数。这三种条件在图3-左中进行了可视化,基准测试集按启用视觉和禁用视觉之间的平均分数差异进行排序。SQA-I{3}、MMMU、MathVista和AI2D在启用视觉和禁用视觉之间的差距小于 5 5% 5,这表明这些基准测试集可能并不显著依赖于视觉输入,而是更多地依赖于基础LLM。TextVQA和GQA在随机猜测和禁用视觉之间的分数差距接近 40 40% 40,暗示这些基准测试集中存在强烈的语言偏见。另一方面,在MMVP和MME Perception等基准测试集上禁用视觉的性能明显差于随机猜测,这表明强烈的视觉基础特别关键。
基准测试集的聚类
为了更好地理解MLLM性能的不同方面,我们分析了我们的23个MLLMs在每个基准测试集上的性能之间的相关性。一个混淆矩阵(图15)揭示了某些基准测试集,如MMMU,与其他基准测试集的相关性很低。我们对基准测试集得分进行主成分分析,并观察到形成了与“通用”、“知识”、“图表与OCR”和“以视觉为中心”类别相对应的聚类(图3-右)。我们根据MMMU包含的问题类型将其归入知识类别(见附录B)。我们还发现现有的以视觉为中心的基准测试集[117,128]规模不足(见图3-右),这挑战了评估此类能力的稳健性。此外,这些基准测试集没有涵盖如深度和空间感知等关键视觉元素。
3.2. 坎布里亚视觉中心基准测试集(CV-Bench)
为了解决现有以视觉为中心的基准测试集的局限性,我们引入了坎布里亚视觉中心基准测试集(CV-Bench)。CV-Bench提供了2638个经过人工检查的示例,比其他以视觉为中心的MLLM基准测试集提供了更多的示例——是RealWorldQA[128]的 3.5 3.5 3.5倍,是MMVP[117]的 8.8 8.8 8.8倍。通过重新利用标准的视觉基准测试集[16,72,145],我们可以在多模态环境中评估模型在经典视觉任务上的表现。利用基准测试集丰富的真实标注,我们制定了自然语言问题,以探究模型对基本2D和3D理解的能力。
如图4所示并在表1中详细列出,CV-Bench通过空间关系和对象计数来评估2D理解,通过深度顺序和相对距离来评估3D理解。
CV-Bench的构建
下面,我们描述为每个任务程序化构建问题的过程。为了确保可靠性,我们还手动检查每个问题,删除那些不清晰、模棱两可或错误的问题。详细情况见附录C。
空间关系(2D)。我们考虑包含两种不同真实对象类别的图像,并使用视觉提示(边界框)来避免在存在多个实例时出现歧义。在这些问题中,我们指定一个锚定对象,问题询问的是相对于这个锚定对象,另一个对象的方向。
对象计数(2D)。这测试了模型计数对象的能力。在为这些问题生成选项时,我们构造了与正确答案相似的多选题选项。例如,如果正确答案是4,选项可能是 2 , 3 , 4 , 5 , & 6 2,3,4,5, \& 6 2,3,4,5,&6。我们还包括了存在性检查示例,其中正确计数是 0 0 0。
深度顺序(3D)。我们考虑包含两个不同类别(即对象A和对象B)的图像,并使用视觉提示(例如,带有两种不同颜色的边界框)来避免歧义。
我们定义“更近”如下:只有当对象A的最远顶点比对象B的最近顶点离相机更近,并且超过一定的偏移量时,我们才认为对象A比对象B离相机更近。
相对距离(3D)。我们考虑包含三个不同类别(即锚定对象、对象A和对象B)的图像,并使用视觉提示(例如,带有三种不同颜色的边界框)来避免歧义。只有当A的顶点的最远距离比B的顶点到锚定对象的最短距离短,并且超过一定的偏移量时,我们才认为对象A比对象B更近。
发现2:现有的视觉基准测试集可以有效地重新利用为视觉问题回答(VQA)问题,从而评估以视觉为中心的MLLM能力。
3.3 指令调优配方
多模态大型语言模型(MLLMs)始于预训练的LLM(大型语言模型)和视觉主干网络,并通过连接器(如投影器MLP)将这些模块连接起来。原始的LLaVA模型[73, 75]提出了一种两阶段的冻结训练过程:首先,使用适配器数据(如基于描述的VQA)在冻结的LLM和视觉主干网络之间预训练连接器,然后在使用指令调优数据时同时微调连接器和LLM,同时保持视觉编码器冻结。关于MLLMs的最佳训练方法,不同的研究[22, 56, 74, 91]得出了不同的结论。在这里,我们通过大量实验重新探讨了这个话题。
在我们的实验中,我们使用Vicuna-1.5-7B作为LLM主干网络,并使用我们的23个视觉模型(如表9所示)作为视觉编码器来调优一组MLLMs。我们在所有实验中都使用了一个包含737K条指令调优数据的混合数据集(见附录F)。每个实验设置中的所有超参数都是一致的,以突出显示使用不同视觉编码器时不同调优策略的影响。所有实验设置和结果都在附录D.2中列出。
一阶段与两阶段训练:最近的工作[56]主张跳过连接器预训练,声称这“减少了计算成本而不会损害下游性能”。为了探究这一说法是否成立——尤其是在使用非语言监督的视觉编码器时——我们使用了0、0.5M和1.2M条适配器数据进行了实验。遵循LLaVA的配方[75],我们在第一阶段仅使用适配器数据在连接器上进行调优,然后在737K条混合数据集上进行指令调优时解冻LLM和连接器。图5显示,首先预训练连接器可以提高模型性能,并且更多的适配器数据会进一步提高所有领域的性能。因此,我们随后采用带有1.2M条适配器数据的两阶段训练作为我们的标准设置。
发现3:两阶段训练是有益的;更多的适配器数据会进一步提高结果。
冻结与解冻视觉编码器:在微调期间冻结[56,73,75]或解冻[38,74]视觉主干网络也存在不同的做法。有人认为解冻视觉主干网络会显著降低性能[56]。然而,我们的实验表明,解冻视觉编码器在所有基准测试中都有利于性能提升,除了在知识基准测试中仅有轻微变化(如图5所示)。我们怀疑这是由于 737 K 737 \text{~K} 737 K条指令调优数据的组成以及这些基准测试中LLM的重点(见第3.1节)导致的。我们注意到,解冻视觉主干网络会增加额外的计算开销,这在当前的分片策略下禁止了对一些较大的视觉模型进行测试(更多细节见附录F)。
发现4:解冻视觉编码器广泛有利。受语言监督的模型始终受益;特别是在以视觉为中心的基准测试中,自监督学习模型特别受益。
3.4. MLLMs作为视觉表示评估器
如之前章节所述,MLLMs提供了一个新的界面,用于探索传统基准(如ImageNet-1k线性探测)之外的视觉模型方面。我们研究了使用 1.2 M 1.2 \text{M} 1.2M条适配器数据、 737 K 737 \text{~K} 737 K条微调数据和冻结的视觉编码器设置的2阶段指令调优,以便对最广泛的模型进行比较。
我们在第3.1节中详细描述的基准测试中进行了评估,计算了每个类别的平均性能 5 {}^{5} 5,并将结果可视化在图6中(完整结果见附录D)。我们的发现强调了语言监督模型相较于非CLIP模型在所有基准测试类别中的优势,特别是在图表和OCR相关基准测试中表现显著更好。我们假设这是由于CLIP的训练数据,如LAION[107],包含了大量的OCR和文本密集型数据,而SSL和其他视觉模型主要训练在文本内容显著较少的自然图像上。值得注意的是,语言监督模型通常使用非常大的数据集进行训练,范围从4亿[102]到100亿[23]个样本,而最大的视觉自监督训练数据集,如DINOv2,仅包含1.42亿个样本[96]。
图6中DINOv2、其他SSL模型与语言监督模型之间的性能比较凸显了使用更多数据和改进技术训练更优秀的仅视觉模型的潜力。此外,我们观察到高分辨率模型特别增强了图表和以视觉为中心的基准测试的性能,而在一般VQA和知识型VQA上则保持中性。尽管我们检查的大多数主干网络都是基于ViT的[33],但基于ConvNet的架构(如OpenCLIP ConvNeXt[79])天生适合高分辨率图像处理[121],并能在OCR&Chart和以视觉为中心的基准测试中产生更出色的结果。在以视觉为中心的基准测试中,语言监督模型与其他类型的视觉模型之间的差距较小,甚至经过良好训练的自监督DINOv2模型在某些方面超过了某些语言监督模型。
发现5:高分辨率编码器极大地提高了图表和以视觉为中心的基准测试的性能,而基于ConvNet的架构天生适合这样的任务。
缩小语言监督与自监督模型之间的差距
在上面,我们观察到DINOv2在一般基准和知识基准测试中位于自监督模型与语言监督模型之间,甚至在以视觉为中心的基准测试中,以更高的分辨率超越了某些语言监督模型。这里,我们研究基于自监督模型的MLLM继续微调是否能达到与语言监督模型相似的性能。鉴于DINOv2的训练数据量远少于CLIP,我们研究在解冻视觉主干网络的同时增加视觉微调数据量,以缩小这一差距。具体来说,我们将指令调优数据从 737 K 737 \text{~K} 737 K扩展到 5 M 5 \text{M} 5M(更多细节见附录E.5),并在冻结和解冻设置下,使用DINOv2 ViT-L/14@336和OpenAI CLIP ViT-L/14@336编码器对MLLMs进行指令调优。在图7中,我们观察到,通过解冻视觉主干网络,使用5M数据微调的基于DINOv2的MLLM超越了使用CLIP模型在0.7M数据上训练的MLLM。此外,在 5 M 5 \text{M} 5M设置下,DINOv2与CLIP模型之间的差距有所缩小。
发现6:语言监督提供了强大的优势,但只要有足够的数据和适当的调优,SSL方法就能缩小性能差距。
3.5. 结合多个视觉编码器
如图6所示,不同的视觉编码器在MLLM性能的不同方面表现出色。在本研究中,我们探索了结合多个视觉编码器以利用其独特表示的潜力,旨在构建一个更强大的MLLM。
鉴于不同的视觉编码器使用不同的架构和图像分辨率,我们在本小节中将它们插值到一个固定数量的视觉标记(576个)上(详细信息见附录D.3)。然后,我们按照类似于[117]中提出的A-MoF方法,将这些标记沿着特征维度进行拼接。结果如表3所示,我们观察到随着更多模型的加入,性能得到了一致的提升。
我们的研究表明,添加一个非语言监督模型(DINOv2)可以改善基准性能,特别是在以视觉为中心的任务中。值得注意的是,即使是OCR基准也从融入DINOv2中受益。这突出了自监督学习模型在补充语言监督模型以实现稳健的多模态理解方面的重要性。详细的结果和配置见附录D.3。
然而,这种简单策略有两个限制:1) 它使用插值,这可能导致信息丢失,特别是在具有高分辨率特征图的视觉编码器上;2) 它通过简单的拼接将每个模型视为等同。因此,我们寻求一种更有效的策略,可以更灵活地利用模型组合,同时减少信息丢失。
发现7:结合多个视觉编码器,包括视觉自监督学习模型,能够增强MLLM在各种基准测试中的性能,特别是在以视觉为中心的任务中。
4. 空间视觉聚合器(SVA):一种新的连接器设计
为了有效地聚合来自多个视觉编码器的特征,并防止插值引入的信息损失,我们使用了一组可学习的潜在查询,这些查询通过交叉注意力层与多个视觉特征进行交互[31]。特别是,我们的方法融入了两种新的以视觉为中心的设计原则:
- 我们通过明确定义查询中每个标记的聚合空间来引入空间归纳偏置。
- 我们在LLM层中多次聚合视觉特征,使模型能够反复访问和整合必要的视觉信息。
我们的新公式灵活地容纳了具有不同特征分辨率的多个视觉编码器,同时在聚合过程中以及与LLM的集成过程中保留了视觉数据的空间结构。下面对该方法进行详细阐述。
为了通过交叉注意力促进信息聚合,我们创建了一个 C C C维的可学习潜在标记 x ∈ R C \mathbf{x} \in \mathbb{R}^{C} x∈RC,并将其重复 L × L L \times L L×L次以形成一个 2 D 2\mathrm{D} 2D网格,作为查询 X ∈ R L 2 × C \mathbf{X} \in \mathbb{R}^{L^{2} \times C} X∈RL2×C。来自 N N N个视觉编码器的视觉特征集合 F \mathbf{F} F作为上下文(即键和值)。我们确保每个视觉编码器的输出分辨率是 L L L的倍数。形式上,第 k k k个视觉编码器的特征图 ( F k ) \left(\mathbf{F}_{k}\right) (Fk)的分辨率为 m k L × m k L × C m_{k} L \times m_{k} L \times C mkL×mkL×C,其中 m k m_{k} mk是一个正整数乘数, L L L是具有隐藏维度 C C C的可学习 2 D 2\mathrm{D} 2D网格的高度/宽度。
为了在交叉注意力期间保持空间结构,我们将查询中的每个标记与所有视觉编码器特征图中的特定子区域对齐。形式上,查询中位于第 i i i行和第 j j j列的标记 x i , j \mathbf{x}_{i, j} xi,j对应于第 k k k个视觉特征图的子区域
F k [ m k ⋅ i : m k ⋅ ( i + 1 ) , m k ⋅ j : m k ⋅ ( j + 1 ) ] ∈ R m k 2 × C \mathbf{F}_{k}\left[m_{k} \cdot i: m_{k} \cdot(i+1), m_{k} \cdot j: m_{k} \cdot(j+1)\right] \in \mathbb{R}^{m_{k}^{2} \times C} Fk[mk⋅i:mk⋅(i+1),mk⋅j:mk⋅(j+1)]∈Rmk2×C
通过交叉注意力,标记 x i , j \mathbf{x}_{i, j} xi,j从 N N N个视觉编码器中总共聚合了 ∑ k m k 2 \sum_{k} m_{k}^{2} ∑kmk2个特征(见图8左侧)。
具体来说,位置 ( i , j ) (i, j) (i,j)处的更新查询向量 q i , j ∗ ∈ R 1 × C \mathbf{q}^{*}_{i, j} \in \mathbb{R}^{1 \times C} qi,j∗∈R1×C计算如下:
q i , j ∗ = softmax ( q i , j ⋅ [ k i , j , 1 , k i , j , 2 , … , k i , j , N ] ⊤ C ) [ v i , j , 1 , v i , j , 2 , … , v i , j , N ] , \mathbf{q}_{i, j}^{*}=\operatorname{softmax}\left(\frac{\mathbf{q}_{i, j} \cdot\left[\mathbf{k}_{i, j, 1}, \mathbf{k}_{i, j, 2}, \ldots, \mathbf{k}_{i, j, N}\right]^{\top}}{\sqrt{C}}\right)\left[\mathbf{v}_{i, j, 1}, \mathbf{v}_{i, j, 2}, \ldots, \mathbf{v}_{i, j, N}\right], qi,j∗=softmax(Cqi,j⋅[ki,j,1,ki,j,2,…,ki,j,N]⊤)[vi,j,1,vi,j,2,…,vi,j,N],
其中
q i , j = W Q x i , j ∈ R 1 × C , k i , j , k = W k K F k [ m k ⋅ i : m k ⋅ ( i + 1 ) , m k ⋅ j : m k ⋅ ( j + 1 ) ] ∈ R m k 2 × C , v i , j , k = W k V F k [ m k ⋅ i : m k ⋅ ( i + 1 ) , m k ⋅ j : m k ⋅ ( j + 1 ) ] ∈ R m k 2 × C . \begin{aligned} \mathbf{q}_{i, j} & =\mathbf{W}^{Q} \mathbf{x}_{i, j} \in \mathbb{R}^{1 \times C}, \\ \mathbf{k}_{i, j, k} & =\mathbf{W}_{k}^{K} \mathbf{F}_{k}\left[m_{k} \cdot i: m_{k} \cdot(i+1), m_{k} \cdot j: m_{k} \cdot(j+1)\right] \in \mathbb{R}^{m_{k}^{2} \times C}, \\ \mathbf{v}_{i, j, k} & =\mathbf{W}_{k}^{V} \mathbf{F}_{k}\left[m_{k} \cdot i: m_{k} \cdot(i+1), m_{k} \cdot j: m_{k} \cdot(j+1)\right] \in \mathbb{R}^{m_{k}^{2} \times C}. \end{aligned} qi,jki,j,kvi,j,k=WQxi,j∈R1×C,=WkKFk[mk⋅i:mk⋅(i+1),mk⋅j:mk⋅(j+1)]∈Rmk2×C,=WkVFk[mk⋅i:mk⋅(i+1),mk⋅j:mk⋅(j+1)]∈Rmk2×C.
这里, W Q \mathbf{W}^{Q} WQ是查询的线性变换矩阵, W k K \mathbf{W}_{k}^{K} WkK和 W k V \mathbf{W}_{k}^{V} WkV分别是第 k k k个视觉编码器对应的关键字和值的线性变换矩阵。
在这里, q i , j \mathbf{q}_{i, j} qi,j是在位置 ( i , j ) (i, j) (i,j)的查询向量,它通过查询投影矩阵 W Q ∈ R C × C \mathbf{W}^{Q} \in \mathbb{R}^{C \times C} WQ∈RC×C计算得出。对于每个视觉编码器 k k k,使用其对应的关键字和值投影矩阵 W k K ∈ R C × C \mathbf{W}_{k}^{K} \in \mathbb{R}^{C \times C} WkK∈RC×C和 W k V ∈ R C × C \mathbf{W}_{k}^{V} \in \mathbb{R}^{C \times C} WkV∈RC×C计算关键字向量 k i , j , k \mathbf{k}_{i, j, k} ki,j,k和值向量 v i , j , k \mathbf{v}_{i, j, k} vi,j,k。由于 ∑ k m k 2 \sum_{k} m_{k}^{2} ∑kmk2个特征被聚合到单个标记中,我们实际上减少了标记的数量。
多层视觉聚合 尽管我们的方法有效地从多个视觉编码器聚合了特征,但在高分辨率输入(较大的 m k m_{k} mk)或多个视觉编码器(较大的 N N N)的情况下,仍然存在潜在的信息损失。在这里,单个标记在聚合过程中需要处理更多的上下文信息。为了防止这种情况,我们通过在大型语言模型(LLM)层中多次插入我们的提议来允许交叉注意力发生多次,从而允许持续访问未压缩的视觉信息(见图8右侧)。
超参数 为了灵活地调整容量,我们引入了两个超参数 D D D和 G G G,它们分别表示在视觉模型与LLM之间使用的跨注意力层的数量和可学习查询的不同组数。直观上,较大的 D D D允许更多的堆叠跨注意力操作来促进聚合过程,而较大的 G G G则能够捕获更广泛的聚合模式。 G G G组查询在并行中分别聚合视觉信息,然后拼接在一起以形成LLM的最终视觉标记。在LLM层内的跨注意力层中, D D D和 G G G总是设置为1。
我们使用之前部分得到的最佳视觉模型组合结果和Vicuna-1.5-7B基础大型语言模型(LLM)来展示SVA模块的有效性。具体来说,我们采用了四种视觉编码器的组合:OpenAI CLIP ViT-L/14@336、SigLIP ViT-SO400M/14@384、OpenCLIP ConvNeXt-XXL@1024和DINOv2 ViT-L/14@518。我们将我们的方法与两个强大的基线进行比较:1) 基于拼接的方法[117]和2) Re-sampler[10, 65],它采用了类似的交叉注意力形式,但缺乏空间归纳偏差和多层视觉聚合。在这里,我们包含了SVA模块的两种变体。标准的"SVA"使用 D = 3 , G = 1 D=3, G=1 D=3,G=1,并在LLM内部以3的层步长插入交叉注意力块。为了隔离空间归纳偏差的优势,我们包含了另一个SVA变体"SVA-no-multi-agg",它不在LLM内部添加交叉注意力块,并设置 D = 3 D=3 D=3和 G = 3 G=3 G=3。表4显示,SVA在所有基准测试类别中都优于两个基线,在OCR和图表类别(需要高分辨率特征理解)上取得了显著改进。相比之下,缺乏空间归纳偏差的Resampler在通过全局交叉注意力将来自不同视觉塔的拼接标记压缩成有限数量的可学习查询时遇到了困难。
我们进一步使用OpenAI CLIP ViT-L/14@336 + OpenCLIP ConvNeXt-L@1024作为我们的基础模型组合进行了消融实验。我们专注于OCR和图表类别,以评估对高分辨率视觉理解的影响。结果显示,通过增加 D D D或 G G G来提高容量可以改善性能,并且通过在LLM内部添加交叉注意力层来允许跨多个层的视觉聚合也能提高性能。更详细的实验设置和分析在附录F中提供。
发现8:空间归纳偏差和LLM与视觉特征之间的深度交互有助于更好地聚合和压缩视觉特征。
5. 用于训练多模态大型语言模型(MLLMs)的指令调整数据
之前的工作强调了在训练多模态大型语言模型(MLLMs)中数据的重要性[38, 73, 91],但具体的调查研究还很有限。在这里,我们收集了所有可用的指令调整数据,并通过增强多样性、平衡来源和改进混合比例来检查数据整理。除非另有说明,否则实验涉及使用OpenAI CLIP ViT-L/14@336px视觉编码器[102]与Vicuna-1.5-7B LLM基础模型[142]进行微调。
5.1 数据收集
从现有数据源中收集指令调整数据 与语言数据不同,多模态(视觉)指令调整数据更为罕见且难以收集。为了解决这个问题,我们利用现有的涉及视觉交互数据的多模态基准和数据集,如视觉问题回答(VQA)和OCR数据。之前的工作[138]强调了在微调多模态LLMs时经常发生的灾难性遗忘问题。为了帮助维持对话能力,我们还收集了一小部分高质量的仅语言指令遵循数据。我们将数据分为通用对话、OCR、计数、代码、数学、科学和仅语言数据几类。我们在图9中列出了数据源,并在附录E中详细说明了数据准备过程。
目标互联网数据收集引擎 如图9所示,数据分布存在不平衡。一些类别,如科学,只有很少的数据源,并且每个源的样本数量有限。在现有的数据源中,PathVQA[46]有 32 k 32 \mathrm{k} 32k个样本,而ScienceQA[84]只有12k个样本。这种稀缺性可能是由于生产大规模且可靠的科学视觉指令调整数据的难度。之前的工作[66]已经展示了使用互联网自动收集针对特定任务的目标视觉数据的潜力;我们采用类似的想法来解决这种稀缺性,引入一个数据引擎来创建大规模、可靠、高质量的基于知识的指令调整数据(见图17)。该引擎选择一个目标领域和子领域,如“物理”,并使用如GPT-4[95]这样的LLM来识别主题(例如,“牛顿定律”)。然后,它搜索可靠的来源,如维基百科,为每个主题寻找内容。我们发现从维基百科页面提取的图像-文本对质量很高。一个解析器提取图像-标题对,并将标题文本输入到如GPT-3.5[94]这样的LLM中,使用设计的提示来生成关于图像的指令类型 Q & A \mathrm{Q} \& \mathrm{~A} Q& A对。这些 Q \mathrm{Q} Q和 A \mathrm{A} A对与图像一起构成了我们的VQA数据集。具体细节见附录E.3。我们的数据引擎产生了大量可靠的科学数据,增加了数据池中的多样性。我们生成了 161 k 161 \mathrm{k} 161k个与科学相关的数据点,比之前的综合数据源增加了 400 % 400\% 400%。
Cambrian-10M 我们创建了一个大型指令调整数据池,我们称之为Cambrian-10M。这个数据池包含大约 9784 k 9784 \mathrm{k} 9784k个数据点,为我们的工作和未来的研究提供了多样化的数据。我们在图9中可视化了其组成。
5.2. 数据整理
Cambrian-10M是一个大型指令调整数据池,它来自各种数据源,不同类别之间的数据比例不平衡。在这里,我们采取初步步骤来研究数据整理,通过改进数据平衡和调整数据比例来实现。
数据平衡 我们遵循之前的工作[102,129],为来自单个数据源的数据点数量设置阈值
t
t
t。为了研究阈值
t
t
t的影响,我们绘制了按计数从尾部到头部排序的条目的累积和(见图10)。在本节中,我们选择了$t=$150k, 250k, 350k和450k,并在表6中观察到“肘部效应”——发现阈值在250k和350k之间对于Cambrian-10M效果最佳。
数据比例 与之前VLM数据整理工作[36, 129]通过从互联网上抓取嘈杂的原始图像-文本对进行整理不同,Cambrian-10M是专为视觉指令调整设计的。鉴于不同类型数据的不同能力,平衡这些数据类型的比例至关重要。我们在固定数据集大小为
1350
k
1350 \mathrm{k}
1350k的情况下进行了初步实验,研究了不同数据比例对下游性能的影响。我们将结果可视化在图11中,并总结如下发现:(i) 平衡通用数据、OCR数据和语言数据至关重要。模型的OCR能力与OCR数据比例成正比;然而,过高的OCR比例会损害通用VQA和以视觉为中心的性能。(ii) 知识密集型任务的性能受多种因素影响,通常需要OCR、图表、推理和一般感知的混合。增加科学数据的比例可以帮助,但非常低的比例会导致性能不佳。
Cambrian-7M 通过将我们确定的数据比例应用于Cambrian-10M进行数据过滤,我们创建了一个更小但质量更高的数据集,称为Cambrian-7M。表7展示了经过精心平衡和整理的数据集的好处。尽管样本较少,但Cambrian-7M展示了改进的性能。
5.3. 通过系统提示缓解“答案机器现象”
在这里,我们研究了一种我们称之为“答案机器现象”的现象。我们观察到,训练良好的多模态大型语言模型(MLLM)可能在视觉问答(VQA)基准测试中表现出色,但缺乏基本的对话能力,并默认输出简短、简要的回答(见图12中的示例)。这种差异的产生是因为基准测试问题通常要求回答限制在单个选项、选择或单词上,这与MLLM更广泛和现实的用例相偏离。在其他大型语言模型(LLM)的研究中也讨论过类似的现象[106, 142, 146]。
我们怀疑这个问题源于指令调整数据中包含过多的短回答VQA任务,导致LLM中的灾难性遗忘。为了解决这个问题,我们在训练过程中加入了额外的系统提示。我们在那些产生单个单词或短语的回答的问题前添加了诸如“使用单个单词或短语回答问题”的提示。系统提示的完整细节在附录E.2中提供。在整合了这些系统提示后,我们观察到,虽然模型的基准测试性能保持不变,但其对话能力显著提高。例如,在图12中,带有系统提示的模型在正确回答问题的同时,产生了更长、更吸引人的回答。系统提示还通过鼓励一系列的思考[124]然后给出答案,增强了模型在推理相关任务(如数学问题)上的性能。
这强调了为MLLMs开发评估协议(如Chatbot Arena [29])的必要性,尽管在收集大规模、现实世界交互数据方面存在挑战。尽管在基准测试中表现良好很重要,但同样重要的是确保模型能够进行有意义和自然的交互。整体用户体验和模型的对话能力至关重要,因为那些在基准测试中表现出色但无法有效对话的模型无法满足实际应用的需求。
6. 现有最佳性能
最后,我们利用之前所有研究的见解来训练一系列我们称之为Cambrian-1的MLLMs。我们使用各种规模的LLM主干训练模型:LLaMA-3-Instruct-8B [3]、Vicuna-1.5-13B [142]和Hermes-2-Yi-34B [130]。我们的视觉组件通过空间视觉聚合器(第4节)融合了四个模型——OpenAI CLIP ViT-L/14@336、SigLIP ViT-SO400M/14@384、OpenCLIP ConvNeXt-XXL@1024和DINOv2 ViT-L/14@518(第3.5节)。我们使用 2.5 M 2.5 \mathrm{M} 2.5M适配器数据进行连接器预训练,并使用我们的Cambrian-7M数据混合(第5.2节)进行指令调整。我们的模型在第3.1节中分类的基准测试中进行了评估,结果如表8和图 1 3 6 13^{6} 136所示。
Cambrian-1超越了开源模型,如LLaVA-NeXT和Mini-Gemini。由于SVA的加持,Cambrian-1在需要高分辨率图像处理的任务中表现出色,即使仅使用576个图像令牌——大约是LLaVA-NeXT和Mini-Gemini使用的令牌的 1 / 5 1/5 1/5。Cambrian-1还在多个基准测试中达到了与最佳专有模型(如GPT-4V、Gemini-Pro和MM-1)相当的性能。我们在图14中展示了一些示例,展示了该模型尽管仅使用576个令牌,也能有效地关注图像中的细节。
此外,我们强调对模型输出进行后处理和评估其准确性的重要性。例如,如果正确答案是“(a) Apple”,而模型输出“Apple”,重要的是要识别该响应为正确。我们使用模糊匹配来评估我们模型输出的准确性,并使用如GPT-3.5这样的LLM进行消融研究以验证这种方法。我们的发现表明,模糊匹配提供了可靠的判断。更多细节可以在附录G.2中找到。
7. 讨论
我们主张使用MLLMs作为评估视觉表征的接口,因为以前的基准测试正在变得饱和,并且没有充分反映现实世界多样化和复杂的感知挑战。我们的工作突出了语言监督模型与自监督学习模型之间的当前差距,并展示了弥合这一差距的潜力。然而,已知语言监督模型的特征表现得像词袋模型 [ 116 , 135 ] [116,135] [116,135],这强调了需要改进仅视觉模型以确保更好的视觉理解。我们希望激发未来研究开发更好的仅视觉模型,这些模型旨在适应MLLM设置,更有效地利用大规模数据集 [ 78 ] [78] [78]并保留视觉定位的优势 [ 117 ] [117] [117]。
如表8所示,我们观察到经过良好训练的开源模型,如Cambrian-1,在许多现有基准测试中能够与专有模型相匹敌,甚至超越它们。然而,MLLMs的使用和评估远远超出了当前基准测试的范围,它还包括对话能力、创造力、可靠性和整体用户体验等方面。仅仅基于基准测试结果的模型开发可能会导致一个“答案机器”,它在基准测试中过度优化,但在实际交互能力上却有所欠缺。因此,与人类和社会需求更一致的MLLMs的开发是一个不断发展的过程,无论是在评估还是在模型开发方面。
我们当前的Cambrian-1模型使用了适量的视觉令牌,并且没有采用任何分辨率策略 [ 25 , 70 , 74 ] [25,70,74] [25,70,74]来处理超高分辨率图像或具有极端长宽比的图像,这些图像需要更多的视觉令牌。对于像 V ∗ \mathrm{V}^{*} V∗ Bench [ 127 ] [127] [127]这样的专门任务,需要处理超高分辨率图像,增加分辨率和视觉令牌的数量可以产生Cambrian-1模型的高清版本。
一个很有前景的后期训练对齐方向是通过强化学习而不是监督微调。许多MLLM研究,包括Cambrian,主要关注监督微调。然而,LLMs
[
32
,
97
,
103
,
147
]
[32, 97, 103, 147]
[32,97,103,147]和MLLMs中一些最新进展
[
132
,
137
]
[132,137]
[132,137]表明,从人类或环境反馈中进行的强化学习可以进一步改进模型,有可能超越监督微调的极限,特别是在决策能力方面。
Cambrian-10M(图9和第5节)为研究微调MLLMs中的数据整理提供了一个丰富的数据池。我们的工作在整理更高质量的数据方面迈出了初步的一步,以实现更有效率和效果的指令调整。我们相信在数据整理流程中还有进一步改进的空间,并希望这项工作能为未来的研究奠定基础。
此外,训练大规模模型需要仔细设计模型分片、数据分片和基础设施适应。在这项工作中,我们使用TorchXLA在TPU-V4[53]上使用FSDP[141]来训练我们的模型。我们在附录A中分享了我们的经验、技术挑战和解决方案。我们还开源了我们的实现并提供了教程,以帮助社区更高效地进行大规模训练。
最后,Cambrian-1引入了一系列最先进的MLLM模型,这些模型在多样化的基准测试中取得了顶级性能,并在以视觉为中心的任务中表现出色。我们提供了模型权重、开源代码、数据集以及模型训练和评估的详细指南。我们希望我们的工作能够加强开放研究社区,并加速视觉表示学习和多模态系统领域的未来进步。
致谢
我们非常感谢LLaVA[75]提供的优秀代码库,它成为我们研究的起点。特别感谢Hexu Zhao关于FSDP和大规模训练技术的广泛讨论和知识分享,以及Jiasen Lu关于TPU和JAX分布式训练基础设施的有益讨论。我们也感谢PyTorchXLA团队通过GitHub提供的帮助和回复。
我们感谢Kaiming He关于多模态大型语言模型的早期讨论。我们还要感谢Zhuang Liu、Junlin Han、Yuexiang Zhai、Tianzhe Chu、Daohan Lu、Weiyang Jin、Boyang Zhang和Jiayi Pan对本手稿的审阅。我们也感谢DeepSeek[80]提供的论文模板灵感。
本工作主要得到了Google TPU研究云(TRC)计划和Google Cloud研究信用计划(GCP19980904)的支持。纽约大学IT高性能计算资源、服务和专家团队也提供了额外的支持。S.X.想感谢OpenAI研究员访问计划、Open Path AI基金会和一个亚马逊研究奖的支持。S.T.得到了OpenAI SuperAlignment Fellowship的支持,E.B.得到了NDSEG Fellowship的支持。
A. Training, Infrastructure, and Implementation
All models in this paper were trained using TPU-V4 pods [53]; we evaluate using NVIDIA A6000, A100, and H100 cards. The experiments in Section 3.4 require less than 24 hours on a TPU-V4-128, while our final Cambrian-1 models are trained in less than 4 days on a TPU-V4-512.
To enable and facilitate large-scale parallel training on TPUs, we employ TorchXLA with FSDP [141] to handle training sharding and parallelism. Training a large-scale multimodal model with TorchXLA on TPU is a challenging journey, as there are no open-source codebases and many critical features are not supported in the TorchXLA or TorchXLA FSDP libraries. To provide a brief taste of the difficulties: TPUs require a static graph throughout the program, which requires ground-up rewrites of dynamically-written open-source PyTorch codebases; model resuming is not implemented in TorchXLA, which is especially crucial when training on preemptable TPUs; existing TorchXLA FSDP tutorials fail to compile due to version changes in TorchXLA, updates in Hugging Face Transformers & Accelerate, or simply inherent issues with the tutorial; loading very large models (over 30 billion parameters) with the TorchXLA FSDP library is natively impossible due to the 100GB memory constraints of TPU-V4s, and requires extensive workarounds.
To this end, we have rewritten or developed many new functions to make this research possible. For instance, we rewrote the TorchXLA FSDP Sharding API to load very large models; we implemented model resuming on TorchXLA; we rewrote parts of the Hugging Face Transformers FSDP and gradient checkpointing implementations to enable large-scale FSDP training. We are committed to open-sourcing our codebase and publishing a comprehensive tutorial to share our insights, with the hope of inspiring and supporting future research and open-source contributions to the TPU and TorchXLA ecosystem.
B. Analyzing the Benchmarks
MLLM Benchmark Performance Confusion Matrix
We evaluate the benchmark scores for our one-stage, two-stage finetune-only and hybrid models, and then plot the correlation matrix for the pool of MLLM benchmarks. The correlation plot displays in Fig. 15. The result demonstrates that MMMU is less correlated in measuring model performance to other benchmarks. Nonetheless, we acknowledge it is widely used and therefore cluster it into knowledge-based QAs based on the nature of their questions.
C. Cambrian Vision-Centric Benchmark (CV-Bench)
C.1. Curation Procedure
We provide an overview of the data curation process in Fig. 16, which is conducted in a semi-automatic manner. The procedure consists of two main steps:
First, using the original benchmarks and their associated ground truth annotations, we generate query and answer pairs. These pairs are tailored to specific tasks: 2D-related tasks with COCO and ADE20K datasets, and 3D-related tasks with Omni3D.
Second, after generating the query and answer pairs, we engage human experts to manually filter out any incorrect or ambiguous queries to enhance the quality of benchmark. Each query is assigned one of three statuses: accepted (used as is), modified (where the incorrect answer is modified), and rejected (queries that are ambiguous, such as those too small or difficult to discern, even for human experts).
Following this two-stage process, we finalize the benchmark, which results in a total of 2638 image queries with improved accuracy and reliability. Subsequently, we will discuss the methods of human verification and the evaluation metrics used in this process.
C.2. Human verification
There are multiple reasons for the above generated data to be inaccurate. One of the main reasons is sparse annotations, but occasionally there could be wrong annotations as well.
Thus, we need manual inspection to change/remove these examples generated. Here are a few criteria we followed while manually filtering COCO and ADE20k data.
For Counting question types, if all instances of a category are not annotated, the ground truth would have lower count than the actual number of instances appearing in the image. In a few cases where the image distinctly has different countable instances of the object, we change the options/answer. In case the count is ambiguous, we reject the data sample altogether.
For Relative Distance question types without annotation, if the question is asked about two objects \mathrm{A} and \mathrm{B} and if there are two instances of a specific category (say \mathrm{A} ), the relative location of A w.r.t B can be have multiple correct answers. We reject the sample in this case. We also reject cases with clear incorrect annotations.
C.3. Benchmark Evaluation
To ensure that equal importance is given to both 2 \mathrm{D} and 3 \mathrm{D} tasks, we use an evaluation metric that is the average of the accuracies obtained from these tasks. Specifically, the overall performance is calculated as follows:
\begin{array}{l}
\text { Accuracy }{2 D}=\left(\frac{\text { Accuracy }{C O C O}+\text { Accuracy }{A D E 20 k}}{2}\right) \
\text { Overall Accuracy }=\left(\frac{\text { Accuracy }{2 D}+\text { Accuracy }_{3 D}}{2}\right)
\end{array}
D. Vision Models in MLLMs
As mentioned in Section 3.4, we use MLLM as an interface to evaluate vision model’s different capabilities. Here, we list details in terms of the model selection, full results, and data split.
D.1. Details of Vision Models
In our exploration of versatile vision models, we select thirteen models and group them into four categories: language-supervised models (i.e., OpenAI CLIP [102], SigLIP [136], DFNCLIP [34], EVA-CLIP [113] and OpenCLIP [28]), self-supervised models (i.e., DINOv2 [96], IJEPA [8], MAE [45], MoCo v3 [24]), class-supervised models (ImagetNet22K ViT [33]) and other models such as stable diffusion [104] { }^{7} , segmentation models like SAM [61], and depth estimation models like MiDaS [13]. To provide a clear understanding of the specific variant evaluated, we meticulously detail their backbone architectures, resolution, number of tokens, and hidden dimension sizes in Table 9. For models that output a large number of patches in the last layer (e.g., SAM and ConvNeXt) we interpolate to the number of tokens specified in Table 9, and denote interpolation with \mathrm{I} .
D.2. Full Results of Different Vision Backbone in MLLM
For the above-listed vision models in Table 9, they are integrated as the vision encoder of the MLLMs. These MLLMs are trained on various adapter adapter data splits (i.e., 0,0.5 and 1.2 million), and subsequently fine-tuned on a 737 \mathrm{~K} instruction tuning dataset provided in LLaVA1.5[73]. For the adapter data splits, the 0 \mathrm{M} split indicates that no initial adapter pertaining phase is employed for the MLLM. The 0.5 \mathrm{M} data split utilizes the 558 \mathrm{~K} adapter data from LLaVA-1.5[73], while the 1.2M variant uses ShareGPT4V-PT dataset [22].
0M Adapter Data +737 \mathrm{~K} Instruction Tuning Data As shown in Table 10, we provide 20 results for different variants of the above-mentioned thirteen vision backbones. Among them, language-supervised models show superior performance. Especially, OpenCLIP ConvNeXTXXL@1024 model surpasses all other models on DocVQA with over 12 % , indicating its potential to handle OCR-related benchmarks.
0.5M Adapter Data + 737K Instruction Finetune As shown in Table 11 and Table 10, the inclusion of an alignment stage with 0.5 \mathrm{M} data split results in a notable increase in performance for DFN-CLIP ViT-H/14@378, from 36.21 to 49.94 . This substantial improvement highlights the value of the alignment stage for enhancing certain vision backbones, suggesting its importance in harnessing the full potential of vision models.
1.2M Adapter Data +737 \mathrm{~K} Instruction Finetune As we increase the amount of data in the alignment phase, we observe a consistent performance improvement for SigLIP ViTSO400M/14@384 from 46.79 to 49.72 to 53.09 across 0 \mathrm{M}, 0.5 \mathrm{M} to 1.2 \mathrm{M} data splits as shown in Table 10, Table 11 and Table 12.
1.2M Adapter Data + 737K Instruction Finetune with Unfrozen Vision Model Here, we present the results of different vision models trained with 1.2 \mathrm{~m} adapter data and 737 \mathrm{~K} instruction tuning data in Appendix D.2. Comparing to Appendix G.2, we observe nearly all the models see improvement on most of the benchmarks, especially on the OCR & Chart and Vision-Centric benchmarks.
1.2M Adapter Data +\mathbf{5 M} Instruction Finetune We present the results of 5 \mathrm{M} instruction tuning experiments in Fig. 7 here. In Table 13, we observe that after 5 \mathrm{~m} instruction tuning, the gap between DINOv2 and CLIP models continue to bridge on general, knowledge and vision-centric benchmarks.
D.3. Model Ensemble
Model Ensemble Details We introduce the implementation details of the model ensemble in Section 3.5. For a given image, the image passes through each vision encoder to obtain the features from the last layer. The shape of each model’s output differs depending on the resolution and patch size of each vision model. To resolve these differences, we interpolate the output of each model to a fixed number of tokens, using 576 tokens in our implementation, as described in Section 3.5. Our example code for interpolation can be seen below.
We then concatenate the model outputs along the feature dimension and use a larger MLP to project the concatenated visual tokens into the LLM token space.
Full results on Model Ensemble We present all the benchmarks from the model ensemble experiment in Section 3.5 in Table 3. As discussed in Section 1 and Section 3.4, this comprehensive view of benchmarks provides a better understanding of the model’s performance compared to simply averaging across benchmarks. Adding a vision-only SSL model enhances the MLLM’s performance in vision-centric benchmarks while maintaining strong capabilities in other categories.
E. Data
E.1. Catalog of Visual Instruction Data
Here, we provide a comprehensive catalog of visual instruction datasets utilized in our study. The datasets are categorized based on their primary focus, including general conversation and VQA data, OCR-related data, counting data, knowledge-based data, and language-only data. Table 15 summarizes these datasets and their respective references.
E.2. Additional System Prompts used in Cambrian Data
As our Cambrian data includes instructions/questions and responses of different types and formats (e.g., Short response with a single word or regular response as a complete sentence), it is important to specify the required response format in the instruction prompt to avoid ambiguity and possible conflicts. Some of the datasets already include such prompts and we add proper prompts for the remaining datasets. The detailed response formatting prompts we additionally add are listed in Table 16.
E.3. Data Engine
Comprehensive Implementation Details of the Data Engine
The data engine is designed to generate instruction tuning data for knowledge-based fields, where previous works rarely covers and MLLMs are not reliable to distill for from. The data engine takes in a given field, such as “Physics”, utilizing reliable web sources like Wikipedia. Below are the various stages involved in the process. We also visualize this process in Fig. 17:
Stage 1 - Topic Generation: We start by compiling a list of fields and subfields and subsequently generate topics for each field using a Large Language Model (LLM), such as GPT-4. In this stage, we processed 30 fields, resulting in 3660 topics. We then post-process the output of LLMs into json formats. For example, the topic data for Physics looks like below.
Stage 2 - Filtering Web Data: For each generated topic, we utilize search engine APIs to fetch relevant high-quality web pages. For each topic, we query for 10 relevant links. Thus, we get 36,600 webpages post this stage. Here is an example of the data retrieved for the topic “Electric Field and Electric Potential”:
Stage 3 - Parsing: In this stage, we parse each web page to extract image-caption-text tuples. We aim to identify the blocks containing an image, the image’s caption, and relevant textual content. Below is an example of the parsed data for the same topic, “Electric Field and Electric Potential”:
Stage 4 - Data Generation: We generate dataset in this stage, ensuring high quality. We first filter out data samples with fewer than 50 words in the text. Then, instead of downloading images directly from the links retrieved during web parsing, we download high-resolution images from the original sources. We then convert formats like SVG or GIF into a common standardized format, PNG.
Question-Answer pairs are generated by using LLM such as GPT-3.5 from the image metadata, caption, and contextual text. These Q&A pairs and the image form our VQA dataset. We generated 165 \mathrm{k} data samples. Here is an example of the generated data:
This data engine is designed for scalability and efficiency and is capable of handling extensive data generation tasks using multithreading techniques.
E.4. Full results on data curation experiment
Data Balance via Fitlering t As discussed in Section 5.2, if left unfiltered, the data pool is dominated by noisy, unbalanced data sources such as CLEVR and DVQA, leading to pronounced exponential tails. However, as we apply different t values to filter data from each source, the exponential tails become less pronounced, resulting in a more balanced dataset. We also present all the results in Table 17. t value 250k has the highest average across all benchmarks; 250k and 350k also have the highest performance across many individual benchmarks.
Data Ratio Studies We present the full results of our data ratio study in Table 18. The table highlights the importance of finding an optimal data ratio that balances different aspects of MLLM. Experiment 5 achieves well-rounded performance with its selected data ratio.
E.5. 737 \mathrm{~K} and 5 \mathrm{M} Mixes
0.7M For the 0.7 \mathrm{M} data we used in Section 3.4, We add a small number of OCR and chart data to LLaVA 665 K, specifically 15,501 AI2D, 14,999 DocVQA, and 13,000 DVQA data points. This results in a 737 \mathrm{~K} mix, which covers all categories in training MLLMs. This data mix allows us to study visual representations efficiently.
5.0M For the 5 \mathrm{M} data mixes we use in Section 3.4, we apply data filtering discussed in Section 5.2 and apply t=150 \mathrm{k} on all multimodal instruction data in Cambrian-10M.
F. Implementation Details
Cambrian Models. For our final Cambrian models, we use 2.5 \mathrm{M} adapter data which is comprised of 1.2 \mathrm{M} captioning data from shareGPT4V [22] and 1.2 \mathrm{M} captioning data used in MiniGemini [70].
SVA. We introduce learnable k_{m} \times k_{m} positional encodings in the vision features when k_{m}>1 . Besides, during cross-attention, the query is augmented with a global feature obtained by global pooling over the vision features, which is concatenated with \mathbf{q}{i, j} to better guide the aggregation process. In our experiments, the feature maps of all vision encoders except for ConvNext are interpolated to 576 \times 576 ( m{k}=1 for L=24 ). For ConvNext, we first interpolate the feature maps from its 4 stages to 96 \times 96\left(m_{k}=4\right. for \left.L=24\right) and then channel-wise concatenate them to form its final vision feature map similar to [70].
For experiments in Section 4, we set D=3, G=1 and add cross-attention layers between the layers of LLM with a stride equal to 3. For our final Cambrian models, we set D=3, G=1 and insert multiple cross-attention layers in LLM considering the tradeoff between performance and efficiency. For Cambrian-8B, Cambrian-13B, and Cambrian-34B, the strides of cross-attention layers inside the LLM are 3,4 , and 9 respectively.
G. Evaluation Details
G.1. System Prompts Used in Evaluation
To ensure the reproduction of our results, we also include the system prompts we used in this work. The system prompts for our models can be found in Table 21. Additionally, we release the prompts we used while evaluating our models on the various benchmarks in Table 22. We hope this sets a precedent for future research to improve the reproducibility of benchmark results.
G.2. Ablation Study on Fuzzy Matching Vs LLM Judgement
We use fuzzy matching to evaluate responses in some benchmarks, since MLLMs can answer questions with auxillary phrases. To study the effectiveness of our fuzzy matching, we compare our model accuracy through fuzzy matching with the model accuracy obtained when we use LLM as a grader.
The LLM grader is sensitive to the prompt given to it while grading, and we prompt the LLM (we use OpenAI GPT-3.5-turbo and GPT-4-turbo as our graders) with few shot grading examples, which we notice significantly improves grading accuracy. An example of such a prompt is given below.
We conduct an ablation study on the benchmarks that require fuzzy matching and present the results in Table 20. We discover that fuzzy matching provides reliable results compared to an LLM grader. We recommend using a more capable model (such as GPT-4-turbo) for grading benchmarks that have more subjective responses (such as numbers and words).